Overview
New iOS applications are always coming up in our forensic examinations. I’ve found that commercial tools we commonly use to acquire and analyse data from mobile devices are not able to parse the majority of third party apps. This is an inherent issue with the app update cycle. We can’t really blame those commercial products or developers, they really are fighting a futile battle.
So for this piece of testing, I used some open source tools to acquire a backup of my iPhone 7 running iOS 12.1. I’ve been using Evernote for a number of years but oddly have never really come across it during the course of an investigation.
More recently I have been using the Evernote application on my phone to access shared teaching notebooks created by course instructors and discovered some really interesting artefacts relating to logging and locations.
I won’t go into too much of the information you can acquire from the Evernote plist and database files stored by the application, but here are some of what I consider to be some more interesting findings:
Application Logging
Evernote retains a number of logs relating to application usage on iOS and these logs contain a statement about their intended purpose, which is rather handy:
“The Activity Log contains a detailed list of the steps the Evernote application performs, as well as information about your account, your device and location information (if enabled). Your Note titles, tags, Notebook names and occasionally Note content also may be included. We treat your Activity Log data as confidential, and the terms of our Privacy Policy (https://evernote.com/privacy) apply.If sending your log to Evernote, you may want to email the file to yourself and edit out any sensitive information first.”
Based on this statement alone, it’s clear to me as a bit of a log monkey that I’m going to be drawn to these.
The logs are stored in the following location in iOS:
iOS-Backup/Documents/Logs
As you will see from the log names below, they follow a standard naming convention and a quick look at the file names shows us some useful timeline information. I haven’t used the app particularly often but the dates in the table below, specifically relate to the days in which I was attending the teaching events I previously mentioned.
com.evernote.iPhone.Evernote 2018-04-21--21-39-27-026.log
com.evernote.iPhone.Evernote 2018-05-04--02-28-25-844.log
com.evernote.iPhone.Evernote 2018-05-09--01-59-14-135.log
com.evernote.iPhone.Evernote 2018-05-17--07-12-09-464.log
com.evernote.iPhone.Evernote 2018-07-21--03-38-13-286.log
com.evernote.iPhone.Evernote 2018-08-23--07-51-43-715.log
com.evernote.iPhone.Evernote 2018-11-07--10-17-36-152.log
A simple cat command across these files will allow us to aggregate them for bulk searching:
cat /logs/*.log > /new-logs/All-evernotelogs.log
Some useful information we can gather from these logs includes:
- Evernote username
- Hardware (iPhone Model) and iOS version at the time when the log was created
- Carrier in use when the log was created
- Note titles
There are many timestamps stored in these logs and clearly a fountain of information relating to application functions, user activity and previous devices which may have been used by the subject.
There were a number of entries which I found interesting and these lines contained the text “Preview updated“. In most occurrences, there were note titles appearing but some of the entries appeared to be error entries.
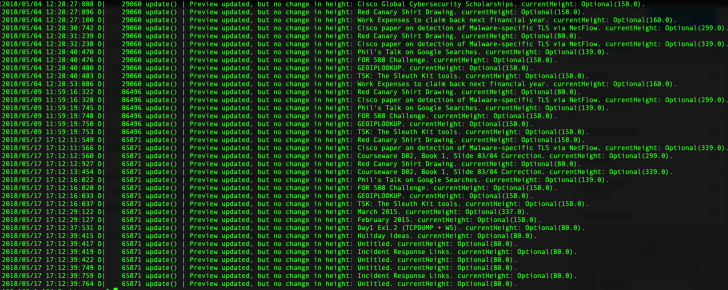
As you can see there’s some repetition here, which is why I believe these log entries directly relate to the previewing of the note that is shown to the user on-screen when the application is launched. This would be useful in proving knowledge of notes or device usage at a specific time.
Geo-locating third parties via Database files
So, when I set out on this journey I expected we might find that there are some databases containing notes and other things like usage history and content. What I didn’t expect to find was very specific information relating to the movements of the individuals who have shared their notebooks publicly.
I pulled the following database out to examine:
iOS-backup/Documents/pending/3*2*9*1-personal-www.evernote.com/LocalNoteStore.sqlite
This database contains a pure mountain of Evernote goodness, which may be of forensic interest:
- Timestamps: note created, deleted, last viewed, last updated and date shared
- Note Author: Often this is the email address used to register the Evernote account
- Last Evernote user to edit a note: As above
- Note Title
- Note URL
- Latitude, Longitude and Altitude for the note creation: If location services are enabled when the note is created
- Source application: iPhone, web browser or Mac (These were the methods I tested, there may be others for Android)
I wrote a quick SQL query to parse out some of the relevant information from the ‘ZENNOTE‘ table which contained all of the relevant note information:
Select DateTime(ZDATECREATED + 978307200, 'unixepoch') as 'Date Created (UTC)',
DateTime(ZDATEDELETED + 978307200, 'unixepoch') as 'Date Deleted (UTC)',
DateTime(ZDATELASTVIEWED + 978307200, 'unixepoch') as 'Date Last Viewed (UTC)'
DateTime(ZDATEUPDATED + 978307200, 'unixepoch') as 'Date Updated (UTC)',
ZAUTHOR as 'Note Author', ZTITLE as 'Note Title',
ZSOURCEURL as 'Note URL', ZLATITUDE as 'Latitiude',
ZLONGITUDE as 'Longitude', ZSOURCE as 'Source',
ZSOURCEAPPLICATION as 'Source Application'
from ZENNOTE
As you will see from the query above and some sample results below, we can determine many timestamps related to specific notes. We can also see the application used to create the note, either mobile or desktop (Source), the author’s name (Note Author), the source URL for the note and most importantly the Geo-location information.

The Evernote shared notebook I identified most of the valuable information was shared by the instructor (Note Author) of a teaching event I attended. This seemed like the most useful for review.
The first thing I did was take a look at one of the locations which featured in the shared notebook and punched the coordinates into google maps to see what was going on.
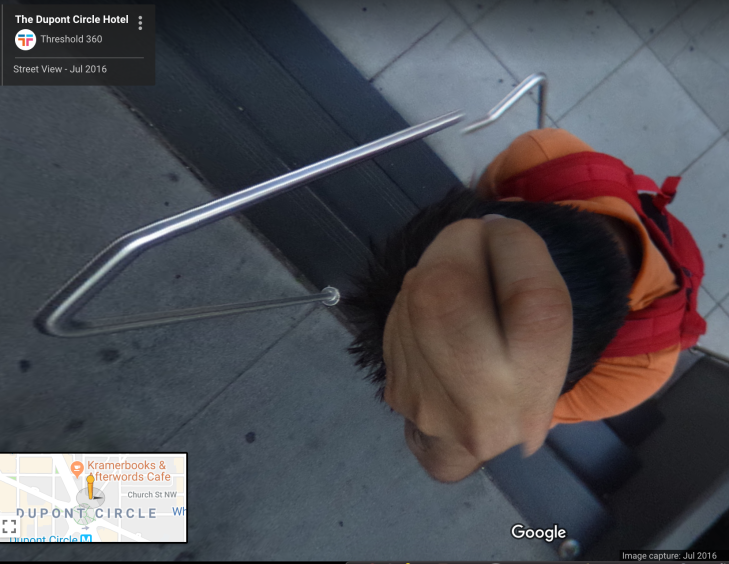
It looks like the Note Author may have spent some time at the Dupont Circle Hotel in Washington back in 2016. It appears from the geo-location information that the hotel was actually mobile at this point and positioned on top of this young man’s melon.
I looked closer at the extracted database entries and quickly identified a number of locations where notes were created or added to the Note Author’s notebook by filtering on the Note Author column. There were a number of entries with locations associated. These ranged from Singapore and London to multiple spots across the United States.
Most of these locations appeared to be hotels, although a residential address appeared a number of times too, which I suspect was the Note Author’s home address.
It should be noted that most of this geo-location information appears to have been added by using the Evernote desktop application rather than the mobile application, although both allow locations to be added to notes. Enabling of location services and sharing of notebooks requires specific user interaction at the time of installation and shared notebook creation.
Why is this information interesting?
- Many different users can add to shared, publicly accessible notebooks
- We can track their activity over time through our own iOS device and EverNote account
What can we deduce?
- Associated email addresses to device/app users (Note Author)
- Other contacts with an individual (Last Edited By)
- Activity relating to the application usage and specific notes (Note Title, Date Created, Date Deleted etc)
- Location information over time (Lat, Long, Alt)
- Devices used by specific individuals (Source)
How could this be abused?
- Nefarious actors attempting to find information about an individual or many individuals, may find ways to scrape URL’s for publicly accessible Evernote Notebooks. This may allow them to leverage this information to gain knowledge of movements, locations such as homes for theft etc.
- Once these Notebooks are subscribed to using an account on the iOS device that the nefarious actor is using, it would be trivial to dump the LocalNoteStore.sqlite file and find out all of this information, including work and business addresses.
Thanks for reading,
Update: Rather than publishing these findings at the end of 2018, I approached Evernote who have since disabled the sharing of note locations in public notebooks. Evernote were kind enough to feature me on their 2019 Security list of contributors.