My last blog post covered some initial things you might run into when choosing to setup analysis systems in the AWS cloud infrastructure.
Since that last writing, I have had some new experiences in capturing evidence across multiple regions and availability zones in AWS, which has certainly given me some new insight which I can share and hopefully be of some use.
Launching an Instance
In AWS EC2 an instance is just a virtual machine, there are a number of host operating systems and configurations available depending on your use requirements. For the purposes of performing evidence collection or analysis in AWS, you should at least have a system with enough storage attached to capture your evidence. Again, the requirements for your evidence collection may change depending on the type of case you are working on, the locations of these evidence sources and other factors, such as time.
To spin up a system, it is as easy as logging into the EC2 console and choosing the instances menu and your AMI image which is a system image with varying host Operating Systems.

It’s worth noting at this point that there is the option to select “Free tier only”. If you, like me, are a skinflint, this is the one for you.

Once you have decided on your AMI, this is when you can choose the hardware configuration of your system.
Try not to get too carried away here…

The next thing we need to do is configure instance details which relate to Networking, scaling, IAM roles and monitoring.
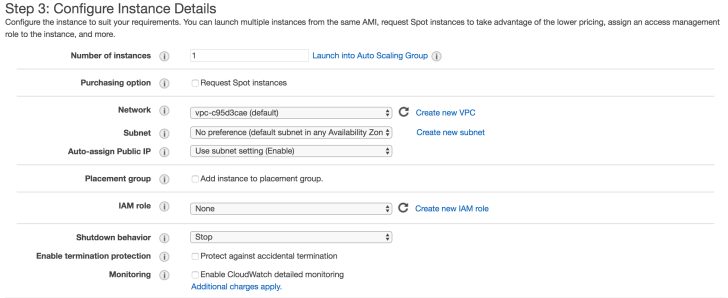
I’m not going to cover everything on this screen but will drop some links for extra reading.
At a very basic level, the options I would pay attention to are:
1: Shutdown behaviour. If you wish to terminate your instance when it is shut down this will erase storage on any local drives. Probably not best to set this if you’re looking to preserve evidence. Great for an attacker.
2: Enable Termination protection. See above.
3: Cloudwatch Monitoring. Cloudwatch is essentially the equivalent of a console access logging and firewall service. Logs from this are highly valuable when investigating as they can show uploads and access to instances or volumes as well as access to the AWS console itself.
While using AWS for performing any forensic analysis or evidence collection, you should absolutely have this turned on. Auditing and logging of your analysis and processes can be assisted massively with this functionality.
4: Tenancy. The option over tenancy may be something you need to consider for legal parameters as this relates to the shared physical storage devices in the data centre where your instance will reside.
Once we have these configurations, we can move onto adding our storage.
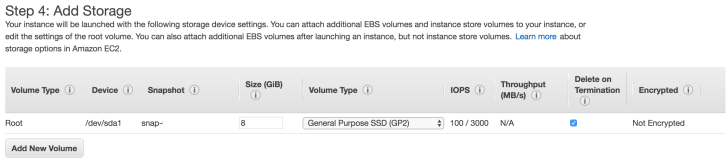
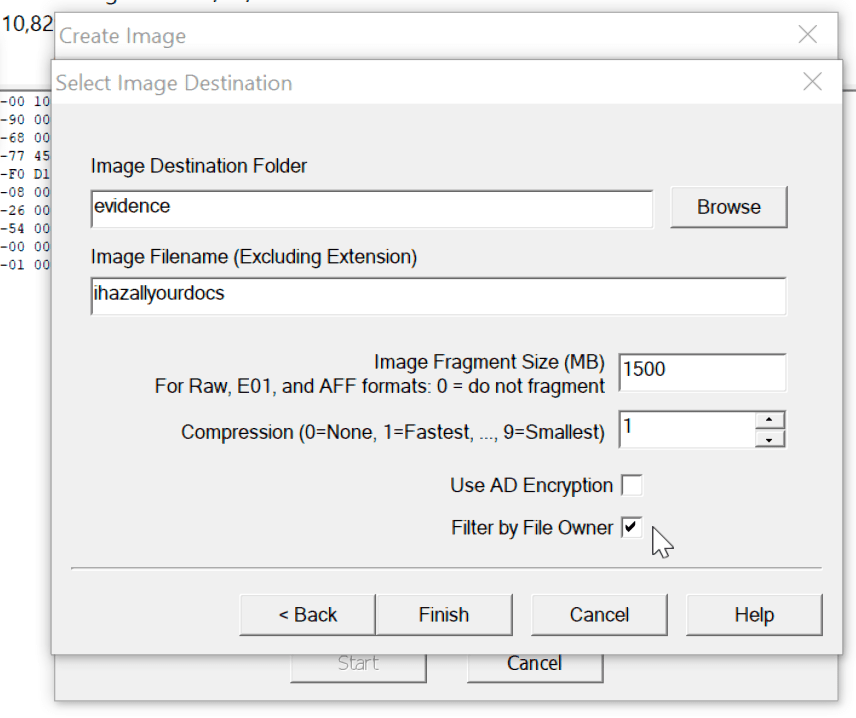
The initial configuration for an Ubuntu AMI in the free tier is 8gb storage. Increasing the boot volume size to at least large enough to store your tools and dependencies is fairly obvious. I’d also attach a volume here to capture evidence to and consider changing the options for “delete on termination”. You can attach and detach volumes later on so if you’re uncertain at this point it is safe to continue without. Encryption of your volume should be fairly self-explanatory.
Creating and adding tags is something I would consider in depth at the earliest outset while scoping your evidence. This is similar to having a naming convention for internal systems in an office or naming evidence exhibits in a case and I found this the best method for maintaining continuity in both of these areas in AWS.

Lastly, we want to lock down access to our instance which is done through “Security Groups”. Security Groups essentially allow us to implement firewall rules to block or allow certain types of traffic via defined IP’s, CIDR blocks, ports and protocols.

For my instance, I have configured the security group to only allow access from my own IP at home and at work.
Once we review our instance we can hit launch and within a few minutes we will have our system up and running. Always remember to shut down your instances when not in use, this can become quite a costly affair for the higher spec instances.

Instance State can be changed by right-clicking on the instance. Notice the ‘Name’ column, this is a defined tag in AWS and how I prefer to specify evidence names and analysis systems.
So that’s about it for spinning up your first AWS instance, next I’ll cover how to connect into your instances using different methods.
Reference:
https://aws.amazon.com/autoscaling/