
A bit about hashing
In digital forensics, hashing is generally used as a method of verifying the integrity of a forensic image or file. The MD5 algorithm has become the accepted standard and used worldwide. Without getting into a long conversational piece about hash collisions and other more reliable and faster methods, MD5 for most purposes is still sufficient.
File hashing has had a long grounding in Law Enforcement cases to identify known good and known bad sets of image file hashes.
Known good hash sets allow an analyst to reduce their data set within their forensic evidence dramatically by removing any files/images related to software and operating systems. NIST has kept the NSRL hash sets updated for a number of years and these among others are widely used to perform this function.
Known bad hashes of images, particularly for indecent image cases are more controversial and have led to many a late-night discussion over how these should be used, managed and categorised.
The major benefit of generating known bad hash set(s) for indecent image cases, is that you are minimising the exposure of the material to the analyst. I believe having a centralised (accurate) hash database to be of utmost importance for the sanity of all those individuals who spend their time categorising images.
The other knock-on effect of using hash sets is that it decreases the analysts time to complete their work, which for overburdened Cybercrime units can only be a blessing.
File hashing can also be used to differentiate files across multiple sources, identifying specific files across evidence sources and assisting with identifying malware (although this is not a full proof approach for malware analysis).
Anyway, on to how we can utilise hashing in X-Ways Forensics.
Hashing in X-Ways Forensics
I’ll start off by making the assumption that you have a basic understanding of how to use X-Ways.
First, you will need to establish a storage location for your hash database(s). X-Ways comes with the option to configure two different databases, this can be useful if you have hashes using different algorithms such as MD5 or SHA1.
Another consideration when configuring the storage location is speed, configuring your databases on an internal SSD RAID would be optimal if you are going to run this locally.
To configure your hash database locations select the following in X-Ways
Tools > Hash Database

Once you have created the databases in your desired locations. You can start to import your hash sets.

You could also create your own hash sets from known good or bad sources, I tend to install fresh offline copies of Windows and create sets from these as I know I can thereafter speak to their integrity. You can also assign a category or hash set name during import, this can be extremely useful when performing differentials.
Please note that if you create any sets from your evidence after your initial hashing you will need to rehash the evidence in order for the new results from these sets to appear.
As you can see from the screenshot below we already have a couple of hash sets added to our database.

Once you have your database configured you can proceed and hash your evidence using the refine volume snapshot feature. This can be done across an entire volume or selected files only.
To perform this function select the following options:
Specialist > Refine Volume Snapshot > Compute Hash + Match against hash database

Once hashing has completed, files which have matched a set can be identified by the light green colour of the file icons.
You now need to configure the directory browser to see the hashes, sets and categories.
This can be done by selecting:
Options > Directory Browser

You will now need to set the directory column size, once this has been set you can adjust by dragging the columns wider or narrower to suit your needs.
After these views have been enabled through the directory browser we can start filtering within X-Ways. From the hash set column, we can enable or disable the ‘NOT’ function to exclude particular hash sets…

.. and from the category column, we can show or hide irrelevant, relevant, notable or uncategorised hash categories.
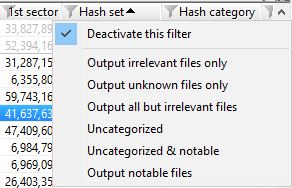

This approach combined with the other filtering functions in X-Ways allow the examiner to cut and dice their output quite extensively. Outputting the directory browser view including the hash sets and categories to csv can allow further review in Excel if that tends to be your tool of choice. This can then quite easily be delivered as a product in your casework.
That’s really it for how I tend to uses hashes in X-Ways.
Useful links and videos for further reference on hashing:
https://en.wikipedia.org/wiki/MD5
https://www.owasp.org/index.php/OWASP_File_Hash_Repository
https://www.nist.gov/itl/ssd/software-quality-group/nsrl-download
https://www.forensicmag.com/article/2008/12/hash-algorithm-dilemma%E2%80%93hash-value-collisions

[…] He walks through hashing files in X-Ways to generate a hash database. Hashing in X-Ways Forensics […]
LikeLike
I find it very helpful how file hashing reduces time spent analyzing data.
LikeLike